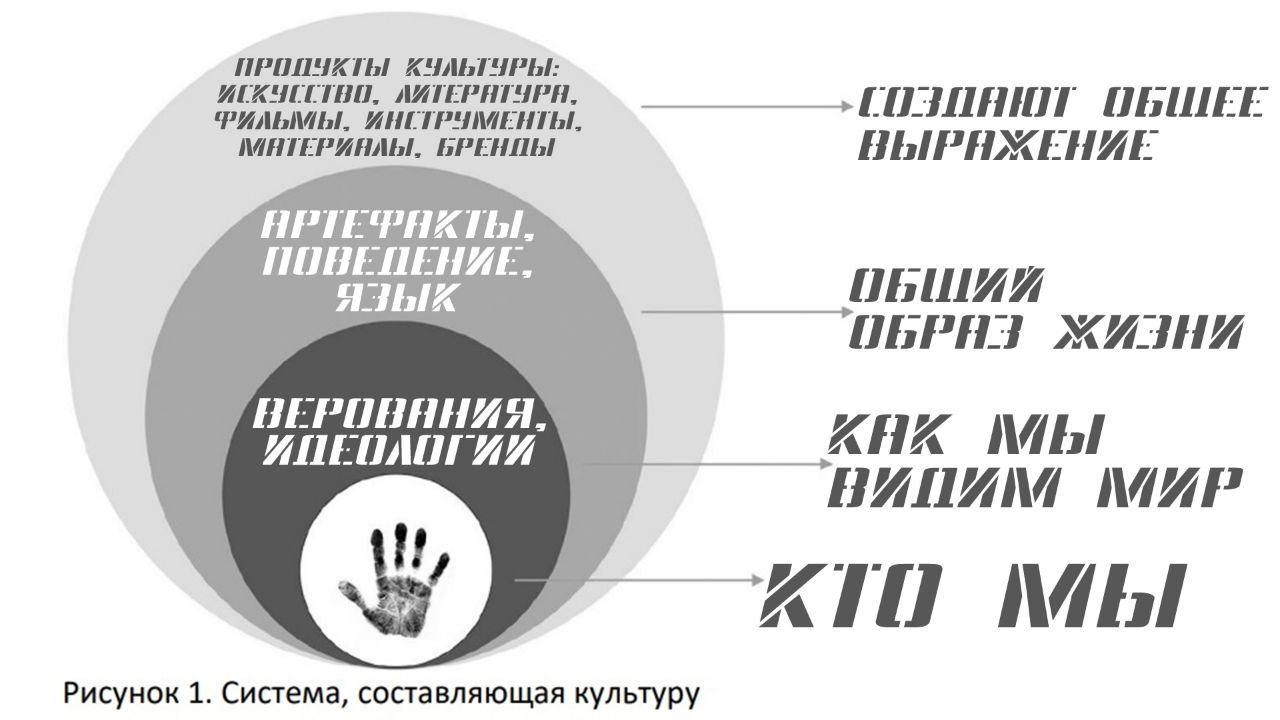
Вырезки из Часть 1. Управление знаниями в Obsidian. Обработка информации. Рабочий процесс. Источники информации. Работа с заметками.
Читаешь ты, смотришь видео, слушаешь подкаст — неважно. В любом случае на тебя льется поток информации. В этом потоке зарыто огромное количество ценных идей/мыслей/наблюдений/возможностей, иногда даже опыт.
Первое и самое важное —
если ты не сделаешь заметку, в которой будет зафиксирована информация, то считай, что ты просто профукал всё озвученное богатство.
Память ограничена.
Идеи невозможно развивать, если не от чего отталкиваться.
Возможности не берутся из воздуха — они формируются вокруг чего-то осязаемого, фиксируемого.
Когда заметки уже есть, то это прекрасно. Однако всё-таки важны не они, а мысли в них. Более того, эти
мысли нужно развивать, двигать куда-то, иначе они будут бесполезными.
Чтобы развивать свои заметки, как бы это не было смешно, но нужны другие заметки. Естественно, что не сами они, а содержащиеся в них мысли. Получается эдакий круговорот и взаимная подпитка.
Каждая существующая заметка может стать вдохновением для написания новой, а новая может дать озарение по отношению старых — своего рода герменевтический круг.
Чтобы наладить процесс формирования новых знаний (заметок), нужно выстроить четкий, последовательный и оптимальный по количеству действий процесс.
Не будет нормального рабочего процесса, не будет эффективности, не будет успехов, короче будет всё так же как и было.
Рабочий процесс трудно объединить под логикой какой-то определенной философии, которая бы смогла отвечать по ходу дела на все насущные вопросы. Однако вопреки этому я скажу, что в формировании новых знаний, есть несколько идей, которые напрямую этому помогают.
Смысл такой — не переусложняй и не перекручивай иерархию, систематизацию, плагины, функции и прочее.
Делай проще. Делай максимально просто.
Хорошей привычкой является вести дневник или в контексте базы знаний — журнал. Его можно использовать как хорошую возможность для связывания каких-то идей. Да и в целом
наблюдение за собой позволяет лучше понимать, что ты делаешь, куда движешься, что в данный момент тебя волнует и т. д.
Понятное дело, что улучшать процесс надо, но порой новые реализации ломают привычный старый и по факту уже достаточно эффективный и что главное прозрачный процесс. Итогом таких неудачных улучшений станет гарантированно раздражение, недоверие к собственной же системе ведения заметок, снижение мотивации, деградация, смерть.
Стоит держать постоянно в голове, что качество нашей базы знаний определяется величиной доверия к ней.
Когда мы слишком всё переусложняем, то начинаем терять ощущение легкого и непринужденного процесса исследования.
Что естественно начинает снижать нашу мотивацию и вовлечённость. В общем логика проста —
не множь сущности без необходимости.
Более того, если перекрутить очень сильно систему, то в неё будет очень трудно что-то добавить. А это значит, что не появится новых идей, новых связей, новых аргументов, чтобы раздолбать наконец-то твоего ультранепробиваемого соседа.
При построении системы очень хочется сразу добавить много логики и каких-то функциональных вывертов, которые на первый взгляд могут казаться просто жизненно необходимыми. Вообще говоря, они и по правде могут являться очень важными и нужными, но не сейчас и не сразу.
Нашей голове нужно давать всегда время на усвоение новой информации или новую технику обработки. Если этого не сделать, то всё, что мы напридумывали и накрутили при любом небольшом перерыве просто развалится как карточный домик и нам придется начинать сначала.
Очевидно, что, как и всякое наше новое начинание, наша очередная попытка создать внятную систему будет иметь большой риск снова развалиться.
Дабы не страдать от своих переделкиных,
нужно строить систему постепенно, т. е. размеренно, не спеша
по ходу дела формируя справочные заметки и более короткие пути к точкам входа.