От точечного графика к ящику с усами

Давайте рассмотрим способы компактного изображения набора числовых данных, которые позволяют увидеть его примерное распределение. Будем работать с одномерными данными, то есть с данными описанными одним значением. Для наглядности, будем показывать на графике одновременно несколько групп значений, что позволит их визуально сопоставить.
Начнем с простого точечного графика.
Точечный график (dot plot)
На точечном графике каждое значение изображено в виде точки. Для того, чтобы точки не накладывались друг на друга, их немного сдвигают в стороны от оси графика.
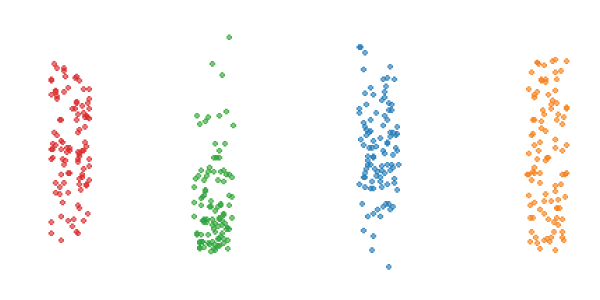
Раньше, когда люди создавали графики вручную, высекая узоры на гранитных скалах при помощи бронзового зубила, построение точечного графика отнимало время. Тогда как очевидное упрощение точечного графика заключалось в замене полосы точек на отрезок. Открытие этого способа изображения данных произвело революцию в умах первобытных людей, привело к расцвету эпохи Возрождения и введению в научный обиход графика диапазона.
График диапазона (Range bar chart)
График выглядит как отрезок или полоса, которая простирается на весь диапазон наличествующих значений.
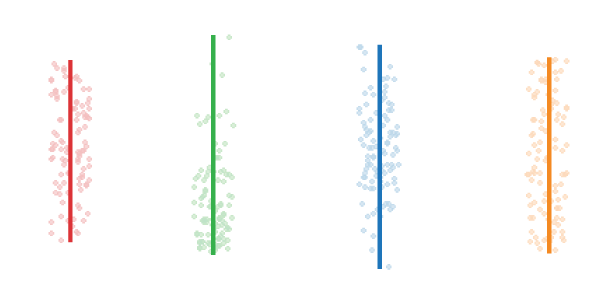
Несколько расположенных рядом графиков позволяют сравнить интервалы значений. Однако вся прочая важная информация о распределении данных остается сокрытой. Так, одинаковые графики диапазонов могут упрощенно описывать совсем разные распределения: нормальное, ненормальное, биномиальное, смещенное, и эти закономерности мы не увидим.
Так продолжалось до тех пор, пока не появилась мисс Мери (Элеонора) Спир (Mary Eleanor Spear).
График диапазона с медианой и квартилями
Мери Спир считается американским пионером визуализации данных. Она издала две книги: «Charting statistics» в 1952 году и «Practical Charting Techniques» в 1969.
В них она подробно описала способы построения и оформления различных статистических графиков.
На странице 166 книги «Charting statistics» она:
- добавила на график диапазона рисочку, показывающую положение среднего значения;
- предложила вместо среднего показывать положение медианы и двух квартилей.
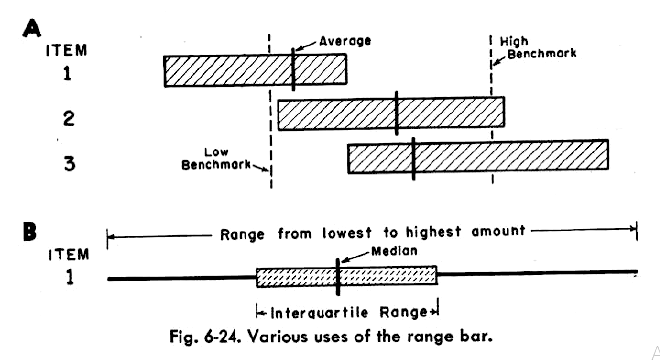
Считается, что именно эти графики впоследствии натолкнули Джона Тьюки (John Tukey) на идею построения диаграммы размаха, более известной в обиходе как «ящик с усами».

Но давайте, буквально на минуточку, отвлечемся от графиков и рассмотрим простой способ числового описания распределения одномерных данных.
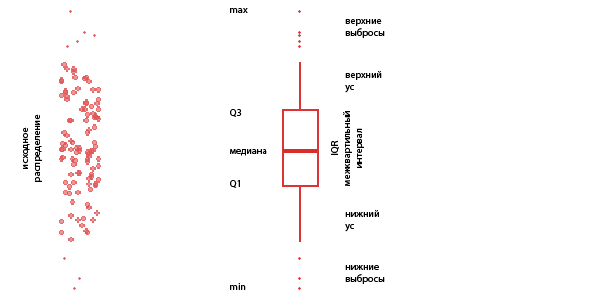
Пятиточеная статистика (Five-number summary)
Любой набор одномерных данных можно компактно ужать до пяти числовых значений, которые очень даже неплохо опишут его суть. Эти значения включают пять основных персентилей:
- минимальное значение (min) — это нулевой персентиль (0%), меньше него ничего нет;
- первый квартиль (Q1) — это двадцать пятый персентиль (25%), четверть данных меньше этого значения;
- медиана или второй квартиль (med, Q2) — это пятидесятый персентиль (50%), половина данных меньше, а другая больше медианы;
- третий квартиль (Q3) — это семьдесят пятый персентиль (75%), только четверть данных больше этой величины;
- максимальное значение (max) — это сотый персентиль (100%), больше него ничего нет.
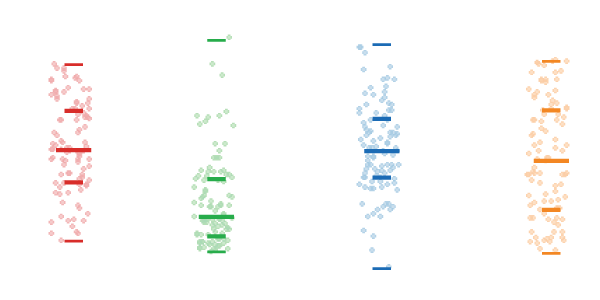
Если упорядочить наши данные по возрастанию, то медиана будет находится точно посредине ряда, а первый и третий квартили точно посредине каждой половины.
Первый и третий квартили позволяют вычислить межквартильный диапазон (IQR, inter quartile range) — в него попадет ровно 50% данных. IQR используется для (не всегда точного) выявления выбросов.
Так вот, Джон Тьюки, насмотревший на графики мисс Спир, придумал изобразить пятиточечную статистику данных в виде пяти соединенных черточек. Так получилась диаграмма размаха.
А откуда взялся ящик с усами (box plot)?
Это название появилось из-за внешнего вида диаграммы размаха. В центре нее находится прямоугольник, границами которого служат первый и третий квартили. Прямоугольник похож на ящик, наполненный 50% значений данных, взятых из середины набора. Внутри ящика всегда располагается медиана. Крайние значения набора данных соединены со стенками ящика отрезками, которые и называются усами.
В русскоязычной научной среде более корректно говорить диаграмма размаха.
Чаще всего усы диаграммы размаха начинают не от крайних значений (минимума и максимума), а от границ диапазона, не содержащего выбросы. Сами выбросы рисуют за усами в виде точек.
О том, как определить эти границы, написано в этой заметке.
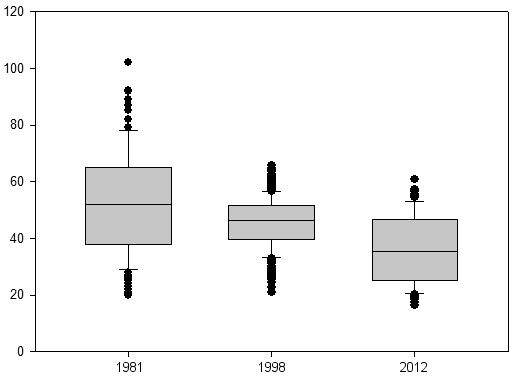
Диаграмма размаха
Внешний вид диаграммы размаха сообщает несколько важных вещей:
- диапазон изменения значений,
- положение медианы — центра данных,
- симметричность распределения.
Расположив рядом несколько диаграмм размаха, мы можем оценить, насколько сильно данные перекрываются.
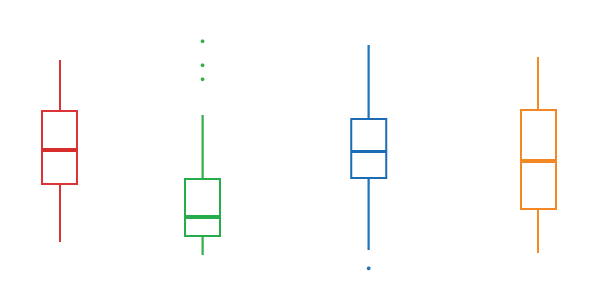
Если медиана одной диаграммы выходит за границы ящика второй диаграммы, то данные будут статистически достоверно отличаться. В иных случаях необходимо выявлять отличия тестами.
Если диаграмма размаха симметричная, медиана находится посредине ящика, усы равной длины и по длине совпадают с длиной ящика, значит кривая распределения данных имеет куполообразную форму и, скорее всего, данные распределены нормально. (Но это не точно.)
А вот если медиана смещена от центра ящика либо длина усов разная, значит распределение в данных ассиметрично. Причем, чем сильнее смещена медиана к краю ящика, тем ближе данные сгруппированы к одному из крайних значений. И чем длиннее один из усов, тем длиннее хвост данных, то есть те значения, которые сильно отличаются от большинства.
Недостаток диаграммы размаха
Диаграмма размаха хорошо показывает разброс и симметричность значений данных, но плохо передает форму распределения. Поэтому возможна ситуация, когда полностью идентичные диаграммы размаха описывают абсолютно разные распределения данных.
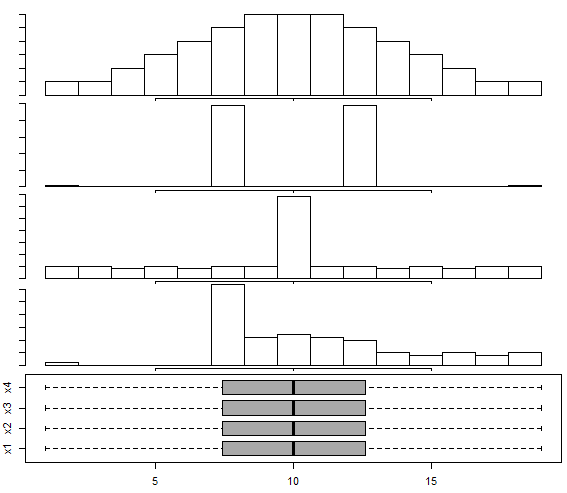
Исправить это досадное недоразумение помогают многочисленные вариации диаграмм размаха, о которых мы поговорим в другой раз.



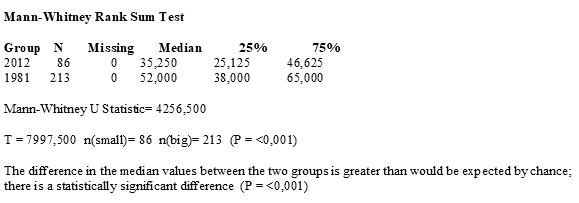









-Mnogomerny-dispersionny-analiz.png)
-Blok-shema-mnogomernogo-disp-i-diskr-analizov.png)
-Primer-formul---2.png)
-Primer-formul.png)
---Dispers-analiza-na-EVM.png)
---primer-2.png)
---primer.png)
-Disp-analiz.gif)
---primer.png)
---primer-2.png)
---Oblozhka.png)
---Uboy-bychkov.png)
---Schelknite-OK.png)