Дисперсионный анализ средних длин раковин моллюсков
Коллега попросил помочь с выполнение дисперсионного анализа. Рассказываю, что получилось.
У нас есть три ряда длин раковин моллюсков, полученные в три разных года: 1981, 1998 и 2012. Мы хотим узнать, есть ли статистически достоверное различие между средними длинами в каждый период или нет? Расскажу, как это сделать.
Сначала посмотрим на статистическое описание данных.
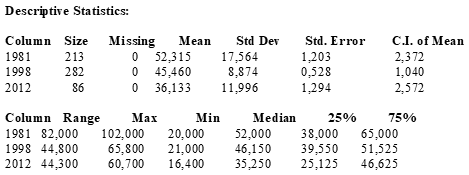
Средние и медианы неплохо отличаются, наверное различия все-таки есть.
Потом построим диаграммы размахов, в простонародье — ящики с усами.
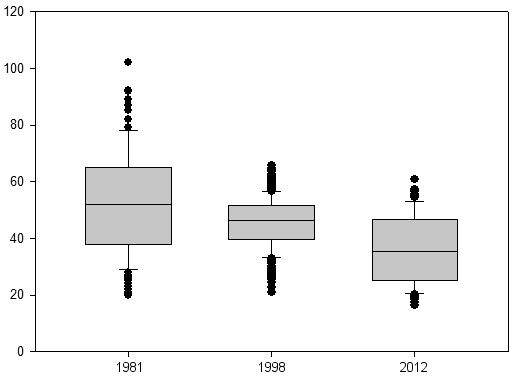
Второй и третий ящики практически полностью пересекаются с первым. Значит различия недостоверны?
Теперь попробуем попарно сравнить средние при помощи t-теста стьюдента: первое со вторым, второе с третьим и третье с первым. Наши данные независимы, потому что мы каждый раз измеряли разных моллюсков. Значит применим t-тест для независимых выборок. Но предварительно проверим данные на нормальность. Если выборки имеют нормальное распределение, используем t-тест. Если ненормальное, прочитаем Сергея Мастицкого (стр. 36):
Если значение распределены ненормально, применение параметрического t-теста будет часто приводить к искаженным результатам. В таких случаях следует воспользоваться непараметрическим аналогом теста стьюдента. Например можно использовать u-тест манна-уитни.
Вперед.
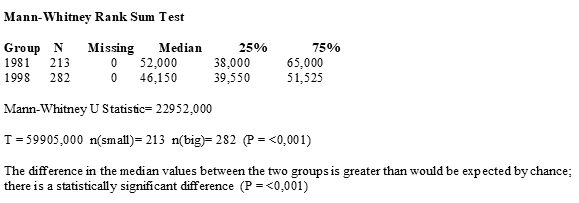
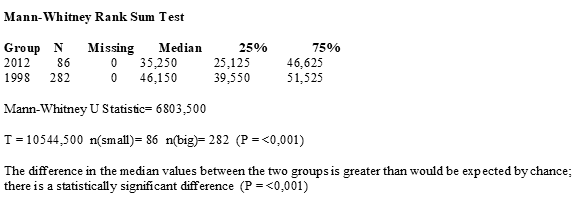
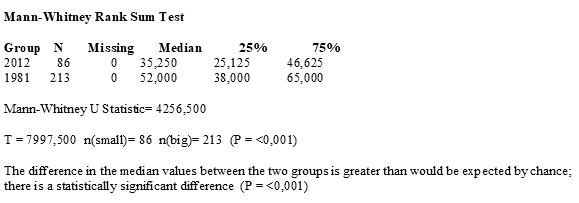
Попарные сравнения показали отличия средних.
А теперь читаем книгу Мастицкого уже на стр. 43:
Тесть стьюдента и его непараметрические аналоги предназначены для сравнения исключительно двух выборок. Очень часто исследователи допускают ошибку: используют t-тест для попарных сравнений более двух выборок.
Надо же, оказывается мы допустили частую ошибку статистических профанов. И как нам быть?
Для избежания данной ошибки необходимо использовать дисперсионный анализ.
Алилуя! Но теперь надо прочитать хорошие книги о дисперсионном анализе?
Нет, совсем не обязательно. Автоматизация статистических вычислений, в настоящее время, достигла таких высот, что вам всего лишь нужно нажать правильные кнопки. Все остальное сделает машина. Например так работает Сигмаплот. Он сам проверит данные на нормальность и выберет правильный тип дисперсионного анализа.
Наши данные оказались ненормальными, поэтому Сигмаплот предложил непараметрический дисперсионный анализ крускала-уолиса (H-тест) и объяснил полученные результаты.

Если бы мы воспользовались Статистикой или Эр, нам пришлось бы интерпретировать полученные цифры. Для этого следует хорошо разобраться в дисперсионном анализе и сопутствующих методах. То есть пройти хороший курс биометрии.
Но тот-кто-знает, что «интерфейс — зло» и «потеть должна машина», тот выберет способ «нажал на кнопку и получил развернутый ответ». Мозги, в этом случае, пригодятся для интерпретации ответа.

Выбирайте сами. И, да — это не реклама Сигмаплота. Просто мне понравилось, как он интерпретировал результат.
Книги, в любом случае, читать полезно.