Стандартизация числовых данных
Это продолжение серии заметок об анализе биологических данных. В прошлый раз мы разобрали понятие объекта и его признаков.
Сегодня рассмотрим процедуру предварительной обработки первичных данных — стандартизацию.
Допустим нам нужно статистически сравнить или сгруппировать несколько наблюдений по схожести признаков (например, выполнив кластерный анализ). Каждое наблюдение — это ряд числовых значений, к примеру, биомасс разных видов организмов. Ряды наблюдений упорядочены: первой всегда идет биомасса вида А, затем вида Б и так далее.
У значений есть особенность: в пределах ряда они могут отличаются в несколько раз, потому что мы изучаем как крупные, так и мелкие организмы. В результате биомасса одного или нескольких видов часто в несколько раз превышает остальные. Как на графике.

Такие наблюдения сравнивать некорректно. Виды, доминирующие по биомассе, будут сильнее всего влиять на результаты сравнения. Поэтому получится, что мы будем сравнивать не биомассы всех видов, а только нескольких доминирующих (в частном случае — одного).
Теперь выполним стандартизацию по видам (по столбцам).
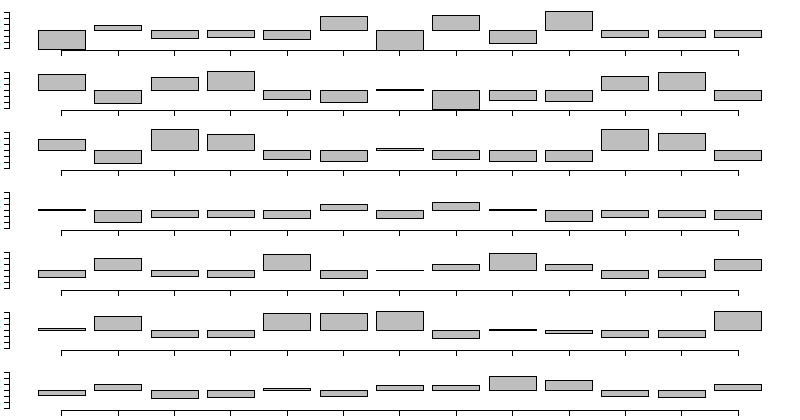
После стандартизации значения выровнялись и исчезло резкое доминирование отдельных видов. Теперь на результаты кластерного анализа будут влиять все значения. А его результаты будут более корректными.
Формула стандартизации
Для стандартизации ряда значений (строки или столбца) необходимо вычислить среднее \( \mu \) и стандартное отклонение \( \sigma \) значений ряда, затем отнять среднее от каждого элемента ряда и поделить разницу на стандартное отклонение:
\( y_i = (x_i — \mu) / \sigma \).
После таких манипуляций среднее ряда станет равным нулю, а стандартное отклонение — единице.
Полученные величины \( y_i \) будут выражать значения в пропорции к стандартному отклонению: то есть 1 будет означать одно стандартное отклонение, 2 — два и т. д.
Код на R
Если вы работаете в R, для стандартизации используйте функцию scale(). Она стандартизирует столбцы переданной матрицы.
standardized_columns <- scale(matrix)Если необходимо стандартизировать строки, транспонируйте t матрицу, а затем транспонируйте результат.
standardized_rows <- t( scale( t(matrix) ) )Когда применять стандартизацию
Обычно стандартизацию применяют, когда диапазоны изменения значения признаков существенно отличаются, как в примере выше. Вот еще несколько рекомендация на английском о применимости стандартизации.